Ai-O Publications
Publications by the Artificial Intelligence In Ophthalmology Center
Tracking Surgeon- and Observer-Gaze as a Surrogate for Attention in Ophthalmic Surgery Heading link
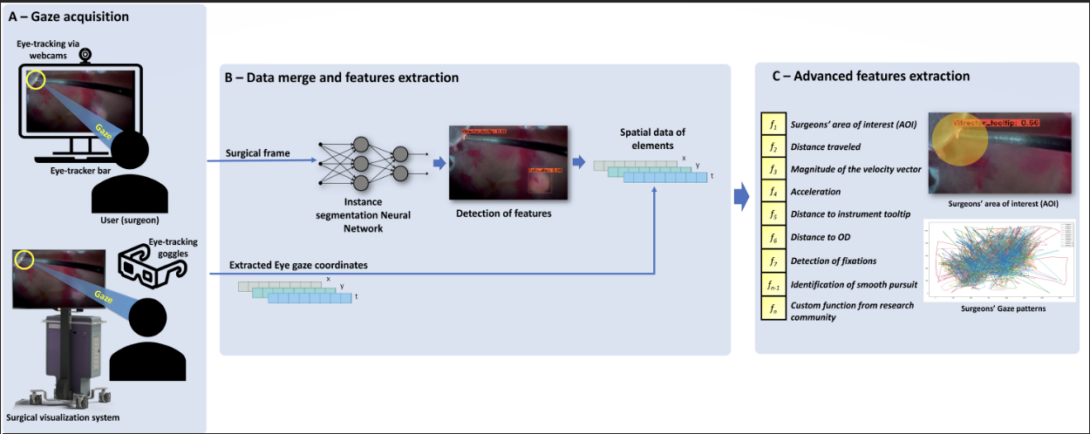
By: RG Nespolo, E Cole, D Wang, D Yi, Y Leiderman
Previous research identified disparities in eye movement between trainee and expert surgeons when watching surgery, improving surgical training for intraoperative decision–making. Although, no study of this kind was performed with ophthalmic surgeons. In this work, we developed and validated a platform that acquires the eye movement of ophthalmic surgeons when watching cataract and vitreoretinal procedures. Artificial Intelligence based tools obtained gaze patterns from the subjects, tracked prominent areas of visual attention such as instruments and retina elements, and performed post-hoc data analysis. Results revealed potential divergence in gaze patterns between attendings, fellows, and residents. In the near future, we hope these data can provide feedback to novice surgeons regarding the visual attention of experts during surgery.
Real-time instance segmentation during vitreoretinal microsurgery Heading link
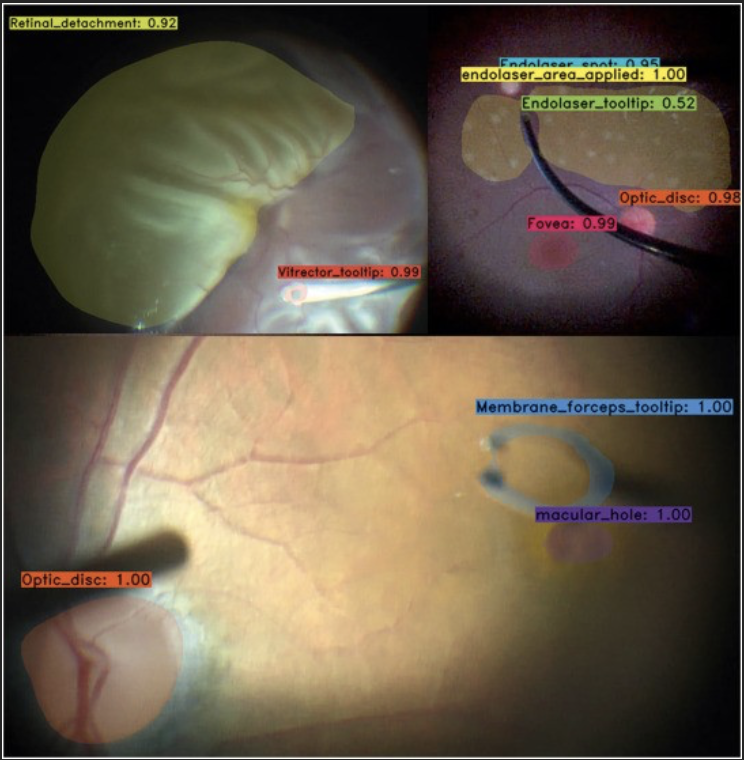
By: RG Nespolo, D Yi, E Cole, A Warren, D Wang, YI Leiderman
The application of AI-based image processing to ophthalmic microsurgery has the potential to improve performance, impact safety, and deepen our understanding of surgical training. The number of these solutions in ophthalmology has vastly increased during the last decade. Although, few solutions have been created with the potential to enhance ophthalmic microsurgery. Our study trained a deep learning neural network to detect, classify, and segment prominent features, such as instruments and tissues, during vitreoretinal microsurgery. The model was validated when integrated into a surgical microscope and visualization system. The results of this study will help researchers to develop and validate ideas using the spatial information pertaining to instruments and tissues, providing the basis for surgical guidance tools such as collision avoidance and semi-automated control of instrumentation parameters. Potential applications of the model also include the assessment of the progression in abilities of trainees via the analysis of instrumentation maneuvers.
Artificial Intelligence–Based Intraoperative Guidance Tools for Phacoemulsification Cataract Surgery Heading link
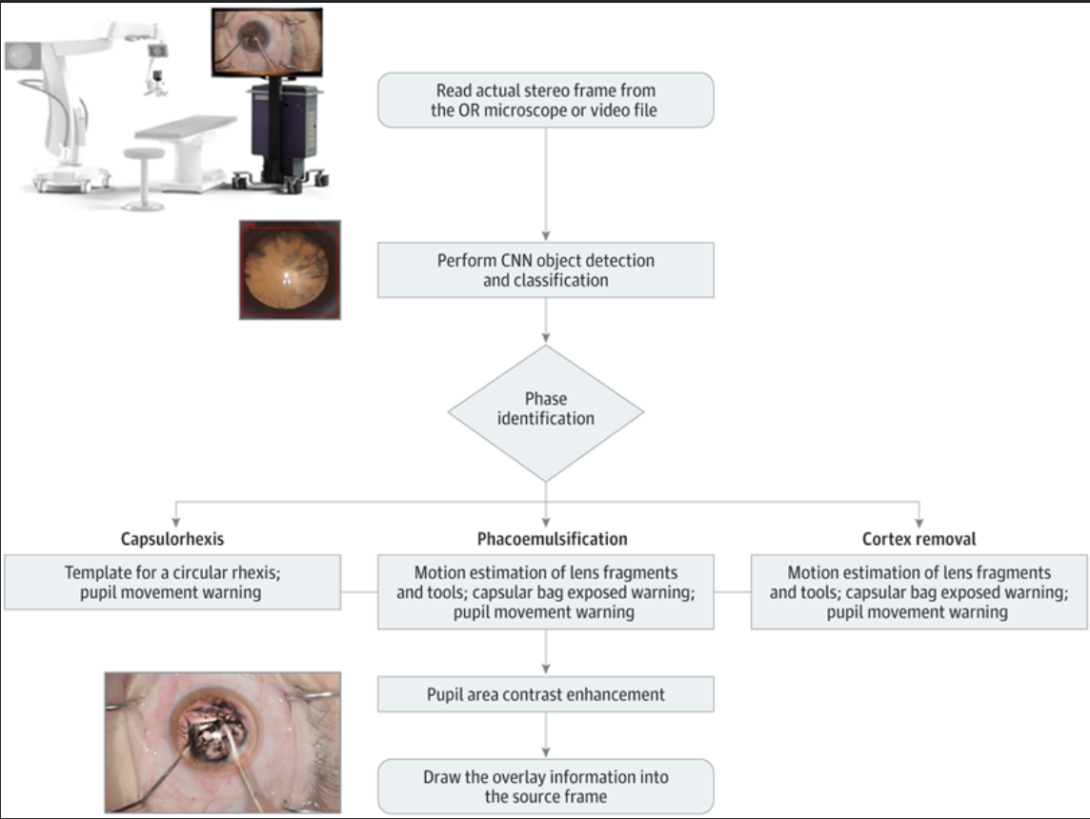
By: RG Nespolo, D Yi, E Cole, N Valikodath, C Luciano, YI Leiderman
Complications that arise from phacoemulsification procedures can lead to worse visual outcomes. Real-time image processing with artificial intelligence tools can extract data to deliver surgical guidance, potentially enhancing the surgical environment. In this study, a computer vision approach using deep neural networks was able to pupil track, identify the surgical phase being executed, and activate surgical guidance tools. These results suggest that an artificial intelligence–based surgical guidance platform has the potential to enhance the surgeon experience in phacoemulsification cataract surgery. Furthermore, this proof-of-concept investigation suggests that a pipeline from a surgical microscope could be integrated with neural networks and computer vision tools to provide surgical guidance in real time.
Auto-Ptosis Heading link
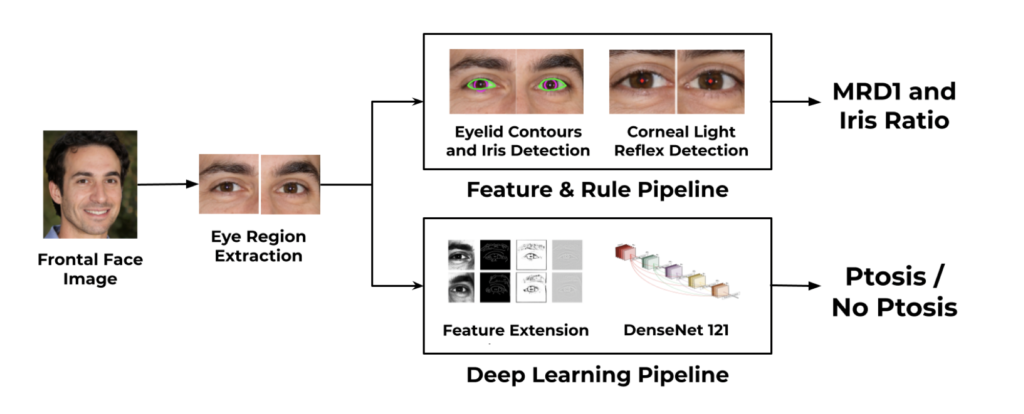
By: Abdullah Aleem, Manoj Prabhakar Nallabothula, Pete Setabutr, Joelle A. Hallak, and Darvin Yi
Blepharoptosis, or ptosis as it is more commonly referred to, is a condition of the eyelid where the upper eyelid droops. The current diagnosis for ptosis involves cumbersome manual measurements that are time-consuming and prone to human error. In this paper, we present AutoPtosis, an artificial intelligence based system with interpretable results for rapid diagnosis of ptosis. We utilize a diverse dataset collected from the Illinois Ophthalmic Database Atlas (I-ODA) to develop a robust deep learning model for prediction and also develop a clinically inspired model that calculates the marginal reflex distance and iris ratio. AutoPtosis achieved 95.5% accuracy on physician verified data that had an equal class balance. The proposed algorithm can help in the rapid and timely diagnosis of ptosis, significantly reduce the burden on the healthcare system, and save the patients and clinics valuable resources.
CvS: Classification via Segmentation For Small Datasets Heading link
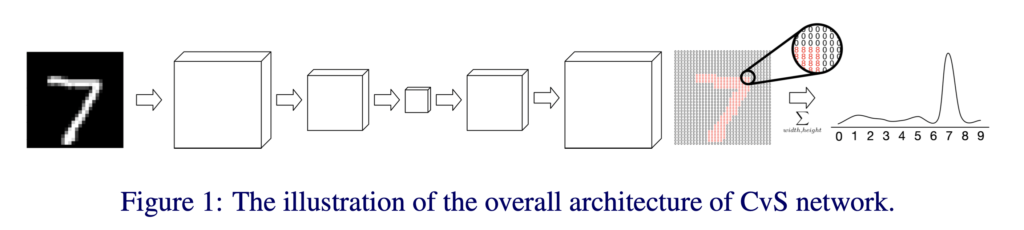
By: Nooshin Mojab, Philip S. Yu, Joelle A. Hallak, Darvin Yi
Deep learning models have shown promising results in a wide range of computer vision applications across various domains. The success of deep learning methods relies heavily on the availability of a large amount of data. Deep neural networks are prone to overfitting when data is scarce. This problem becomes even more severe for neural network with classification head with access to only a few data points. However, acquiring large-scale datasets is very challenging, laborious, or even infeasible in some domains. Hence, developing classifiers that are able to perform well in small data regimes is crucial for applications with limited data. This paper presents CvS, a cost-effective classifier for small datasets that derives the classification labels from predicting the segmentation maps. We employ the label propagation method to achieve a fully segmented dataset with only a handful of manually segmented data. We evaluate the effectiveness of our framework on diverse problems showing that CvS is able to achieve much higher classification results compared to previous methods when given only a handful of examples.
I-ODA, Real-World Multi-modal Longitudinal Data for OphthalmicApplications Heading link
By: Nooshin Mojab, Vahid Noroozi, Abdullah Aleem, Manoj P. Nallabothula, Joseph Baker, Dimitri T. Azar, Mark Rosenblatt, RV Paul Chan, Darvin Yi, Philip S. Yu, Joelle A. Hallak
Data from clinical real-world settings is characterized by variability in quality, machine-type, setting, and source. One of the primary goals of medical computer vision is to develop and validate artificial intelligence (AI) based algorithms on real-world data enabling clinical translations. However, despite the exponential growth in AI based applications in healthcare, specifically in ophthalmology, translations to clinical settings remain challenging. Limited access to adequate and diverse real-world data inhibits the development and validation of translatable algorithms. In this paper, we present a new multi-modal longitudinal ophthalmic imaging dataset, the Illinois Ophthalmic Database Atlas (I-ODA), with the goal of advancing state-of-the-art computer vision applications in ophthalmology, and improving upon the translatable capacity of AI based applications across different clinical settings. We present the infrastructure employed to collect, annotate, and anonymize images from multiple sources, demonstrating the complexity of real-world retrospective data and its limitations. I-ODA includes 12 imaging modalities with a total of 3,668,649 ophthalmic images of 33,876 individuals from the Department of Ophthalmology and Visual Sciences at the Illinois Eye and Ear Infirmary of the University of Illinois Chicago (UIC) over the course of 12 years.